Introducing Nodal.
Enterprise-grade data architecture without the enterprise-sized team
Welcome to Nodal!
Nodal was founded by Mike Berardo and Ron Potok to deliver enterprise-grade data architecture without enterprise-sized teams. Over 20+ years leading data teams & data-driven organizations, we've come to appreciate the importance (and rarity) of business decisions made on top of instantly available, reliable data.
Over the coming months we'll have more to share on our perspectives on data engineering, data architectures, building with AI agents, and related topics, but today we wanted to share a bit about who we are and why we're starting Nodal.
How we got into the data world
Ron
Before "data engineer" or "data scientist" was a job title, before "modern data stack" was a phrase, I was a physicist standing in the middle of a high-tech manufacturing floor at Solyndra, running regression models in JMP or Matlab to optimize complex industrial processes.
I had just finished a PhD in Physics from Harvard, and I found myself in a factory—not in theory, an actual factory in the real world—where thousands of natural experiments were running every day. Temperature drifts, voltage tweaks, subtle differences in material lots… all of it was data. And all of it could be analyzed. We were storing it in Oracle, visualizing it in a brand-new tool called Tableau, and modeling it with early regularization techniques. Back then, as a domain expert with full access to data, I could ask a question, run an analysis, make & execute a decision and deliver business value—all in the same afternoon.
I didn't need a data engineer. I didn't even know what that was. Around 2010, I started calling myself a data scientist. It felt right—an expert using scientific thinking and modern tools to unlock operational wins.
But then the data got bigger. A lot bigger.
As data volumes exploded in the post-cloud era, we moved from relational databases to file-based storage, only to hit new bottlenecks. That shift birthed ETL workflows, Hadoop jobs, Spark clusters, and eventually cloud-native warehouses like Redshift, Snowflake and Databricks. Suddenly, the job was no longer just about asking questions—it was about managing pipelines, orchestrating workflows, and scaling compute. Most domain experts couldn't do that. And so, the data engineer was born.
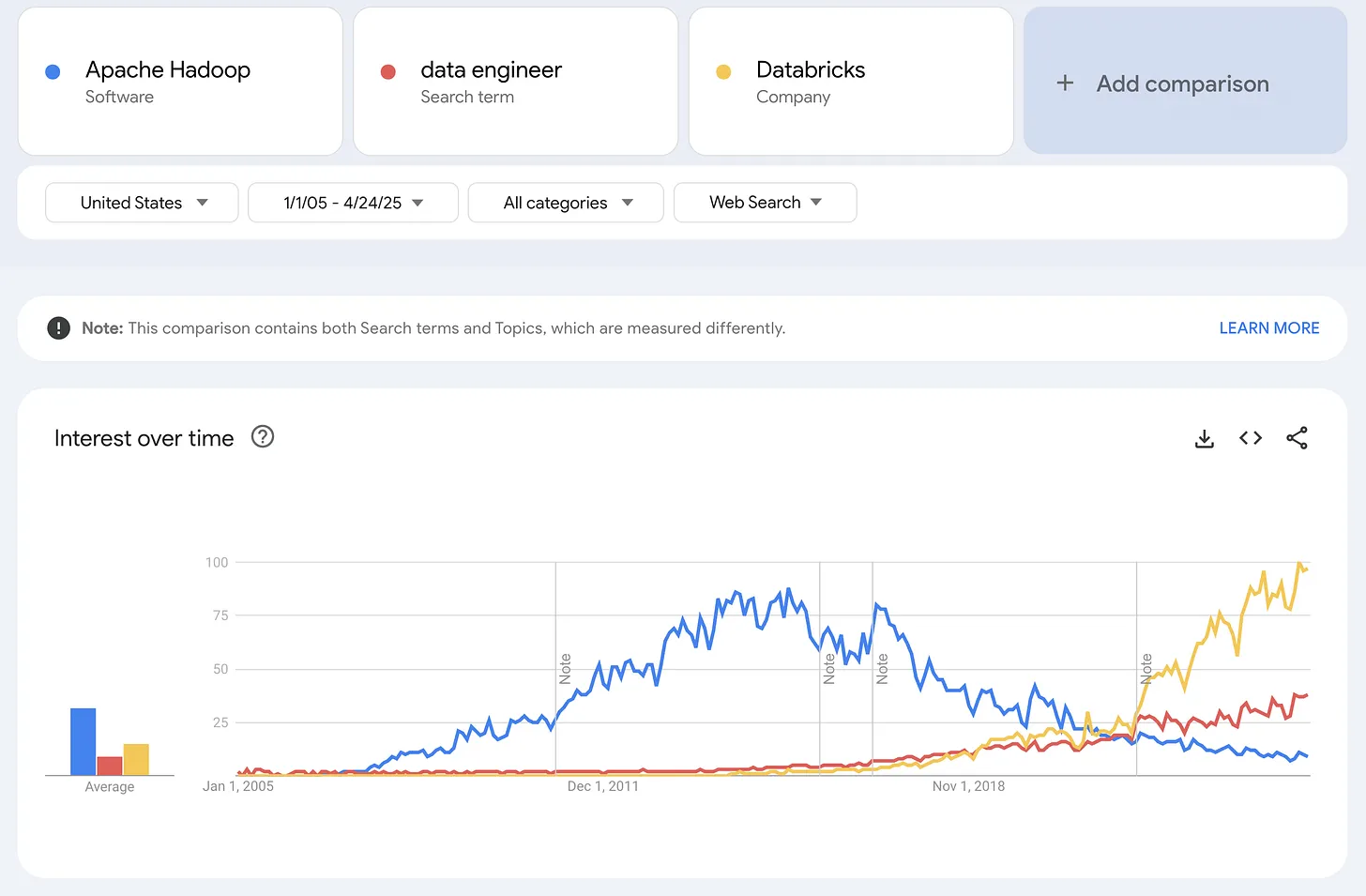
The result? A widening gap between the people who knew which questions to ask, and the systems that held the answers. Data teams grew to fill the space—data engineers, then analytics engineers, analysts, semantic layers, governance tools. And while each new role or tool added value, they also added friction.
Instead of empowering experts, we were insulating them.
I still remember the joy of answering my own questions with data. That direct line between insight and action. Today's tools are technically more advanced, but that speed—the magic—has gotten lost. We've over-engineered the stack and under-served the people who know the business best.
Mike
When I joined Away around its Series A back in 2017 to build out the Data organization, we were one of Fishtown Analytics' first consulting clients. Fishtown Analytics would eventually become the multi-billion dollar data company, DBT, but was at the time the creator of the little-known dbt python package, which helped bring software engineering principles to SQL-centric data teams. They were helping companies like ours implement dbt as a way to model large scale data resources (in our case, marketing attribution data) alongside a new suite of emerging tools that came to be known as the "modern data stack":
- Data warehouses like Snowflake & Databricks
- Business Intelligence tools like Looker
- Data integration frameworks like Airflow and low-code integration tools like Segment & Fivetran
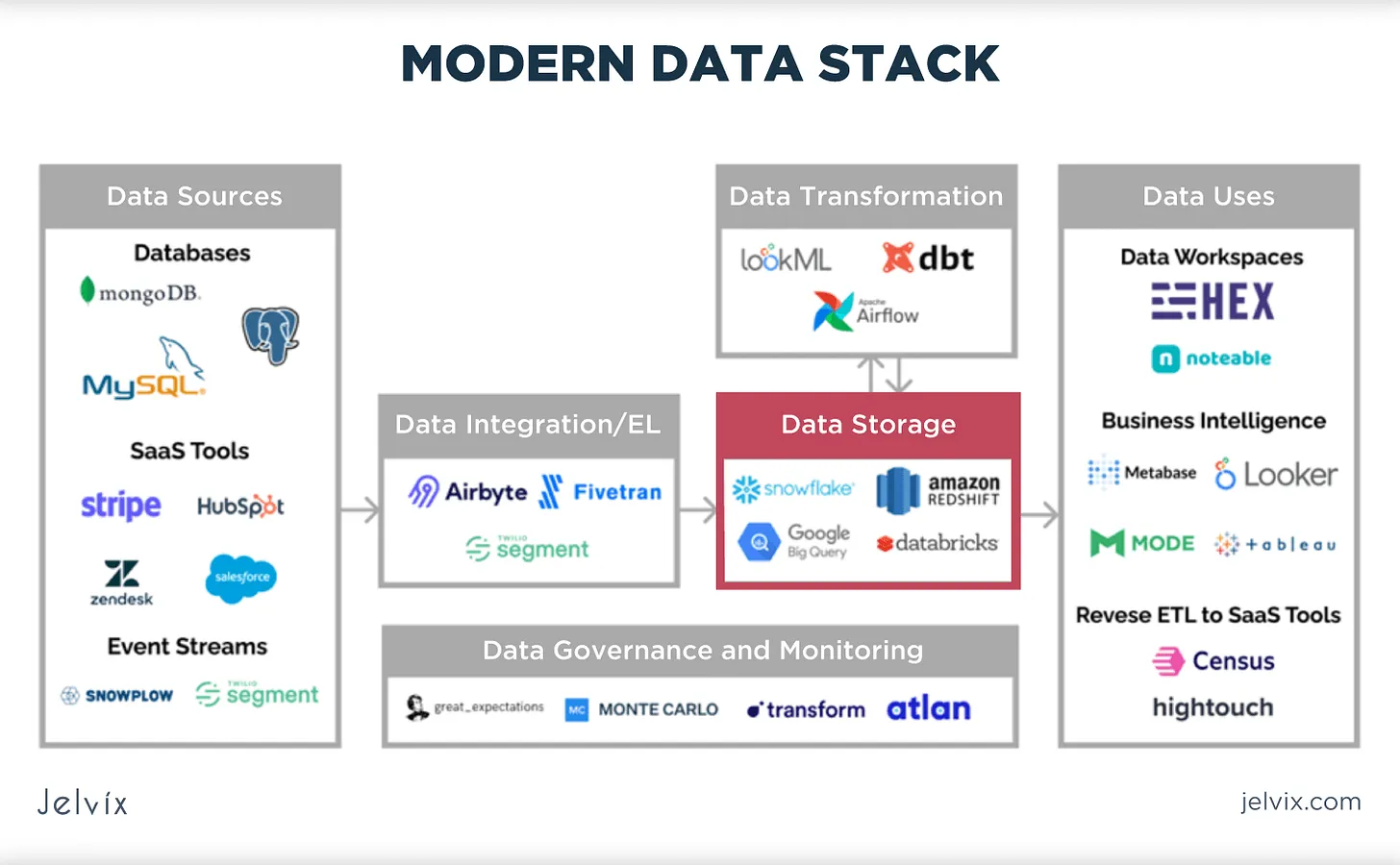
Being new to the space, I didn't fully appreciate at the time that I was coming into the field during a major transitional period. The emergence of this modern data stack directly followed the much-hyped "Big Data" era that Ron mentioned above, spawned by the birth of cloud computing in the late 2000s.
As demand accelerated in the mid-2010s for centralized storage, processing and actioning of a growing set of data assets and systems, the need for a more cost-effective and approachable set of tooling drove the popularity of these newer solutions. That meant massive winners like DBT, Snowflake & Databricks, an entire class of incredible open-source alternatives across the stack, rapid growth in data engineering & analyst headcount, and even entirely new roles like the DBT-created "analytics engineer" to adapt to the changing environment.
Today, I would argue that even as what comprises the "modern data stack" continues to evolve, and even after this explosive decade of growth, its importance is only accelerating. If the "post-Big Data" 2015-2023 era was defined by bringing decision-making efficiency to companies dealing with an increasing sprawl of systems, the last few years have been defined by data teams coming to be seen as a direct revenue driver. Specifically:
- Pushing modeled data to the CRM to unlock Sales, Marketing & Customer Success
- Serving embedded analytics within the company's production application
- Building ML-driven systems like recommendations
- And most recently, enabling generative AI applications
The early-stage dilemma
As a belief in the importance of data best practices has trickled through the startup ecosystem, early-stage founders & leaders increasingly recognize the need for investing in reliable centralized data access. They have a data analyst, or at least someone capable of wearing the data analyst hat. They have product engineers. They've seen which technologies are used at other companies. In theory, it should be easier than ever for them to set up their stack.
In practice, though, the greatest myth of the current era in data is that greater affordability + approachability in tooling would reduce the need for specialized headcount. It's been exactly the opposite.
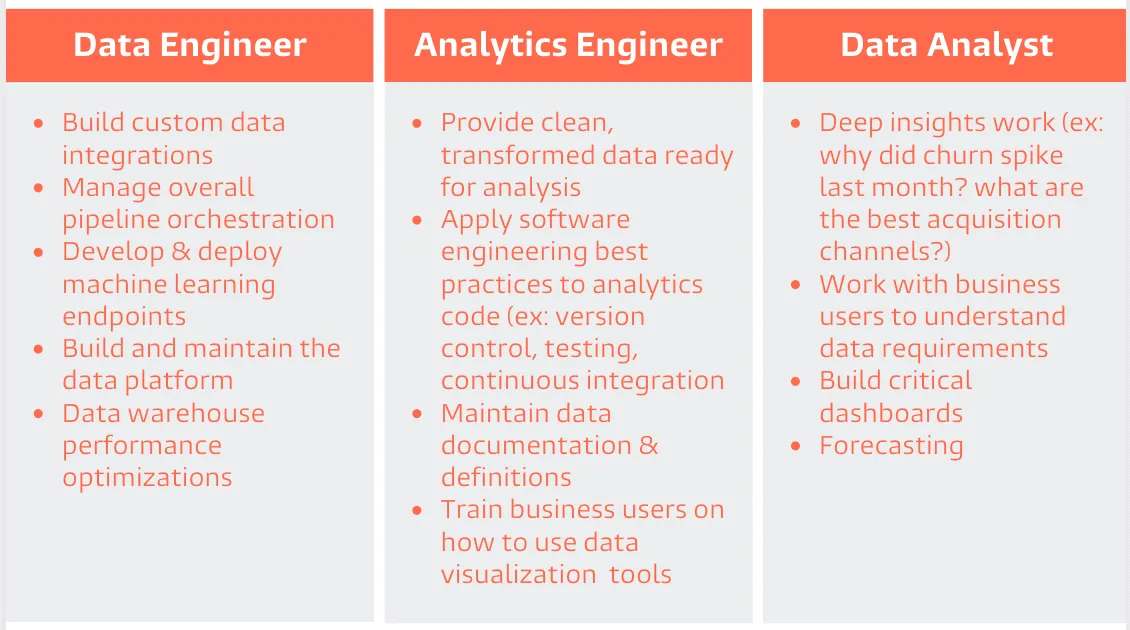
As a result, early stage companies are faced with the following problem:
- You still need at least one reasonably senior data engineer to set up and operate the modern data stack. Your product engineers don't have the time or familiarity, and your analyst does not have the technical capability or expertise to do so.
- One senior data engineer costs at least $200k/year. And they are rapidly going to need help from similarly pricey team members if you want them doing anything but maintaining pipelines.
Companies always need a strong justification to make an expensive hire like this. But it's particularly challenging in early-stage startups that are still so strapped for product engineers to deliver core features. So inevitably they choose the incremental product engineer who can deliver tangible customer-facing features this week over the first investment in a data team & architecture that will compound over time.
This (justifiable) decision usually produces the following unfortunate path:

Introducing Nodal
We think there's a better way, and that's why we're starting Nodal. We believe that if we can solve this tradeoff for early stage companies, we can ultimately improve outcomes for those companies as they grow, and can evolve to serve organizations of all sizes.
Why now?
- Open source tooling exposes the full pipeline: Every layer of the data stack has seen the emergence of powerful open-source tooling - Mage & Dagster for pipeline orchestration, Airbyte for out-of-the-box data connections, Apache Iceberg for marrying the power of data lakes & warehouses. Open source doesn't just mean cost benefits and control - it means that the entire stack is increasingly instrumented either in accessible code or in the data assets themselves. If you build on open-source, nothing (code, schedules, DBT models, semantics) is hidden behind a vendor's walls. Which is important because…
- LLMs are improving at a rapid pace, particularly on coding and data retrieval. The main thing they need is the right context at the right time. Exposing that context unlocks:
- In the immediate term, expert data architects gain massive leverage on all coding/modeling/documentation time with AI copilot tools like Cursor.
- In the medium-term, this will empower an AI agent to drive nearly all key data engineering workflows, with the necessary level of expert oversight & approvals.
At Nodal, we're a team of expert data architects building a data engineering agent, Aiden.
What does Nodal do today?
While we are incredibly excited about the future of AI agents generally and Aiden specifically, our north star is delivering and scaling an amazing data foundation for companies that need it. Not AI for AI's sake.
On day 1, that means an expert-led data pipeline buildout, on your infrastructure, in a matter of weeks. With an architecture and set of technologies tailored to your company. For a fraction of the cost of a single data engineer.
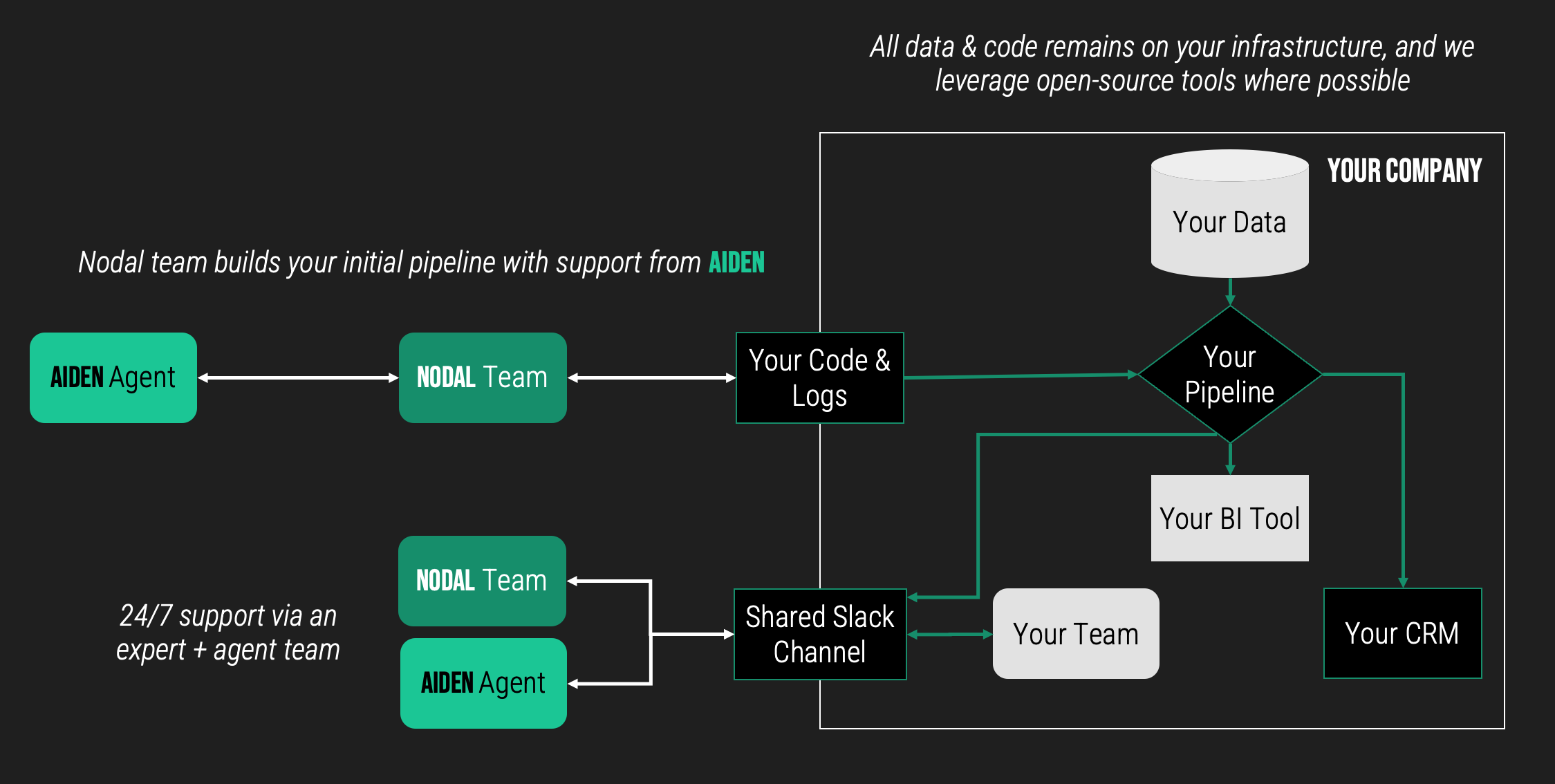
Aiden will help our team move faster with rigorous attention to documentation & best practices during buildout, and will ensure we've got 24/7 pipeline monitoring once the initial buildout is deployed. Aiden is the supporting layer that allows us to cost-effectively bring 20+ years of data engineering expertise to an early-stage company's buildout, not the one in charge.
As Aiden gets better, we move faster, and can deliver both new integrations & maintenance to more companies at a cost and velocity that was just not possible even 1-2 years ago. But it is always an experienced data engineer making the final call.
Where is Nodal headed?
Aiden's initial capabilities have far exceeded our expectations at this stage. Based on that, we see Nodal's future evolution in three phases:
- Nodal + Aiden data foundation: Initially, Aiden will play a supporting role to our expert Nodal team as we focus on building out an initial data foundation and test-driven monitoring layer for early-stage companies.
- Bringing Aiden in-house: While we believe Nodal can get a company as far as 3-5 data engineers typically would with minimal investment, we don't expect that the companies we support will never hire in-house data engineers. We like to call it "staying ahead of the data cost curve." When you would've had 5 data engineers costing $1M+, you'll have one data architect, and they'll be getting leverage from working with Aiden directly. Faster, with higher quality & reliability, saving 6-7 figures/year.
- Augmenting Data Science & Analysis: There are a lot of new companies today popping up in the "AI Data Analyst" space. We get it, it's a big market and a pain point for nearly every company over a certain size. We haven't talked about it as much in this post, but big companies have a whole set of their own data problems - one of the biggest is the volume of ad hoc requests from business teams and the inconsistency in answers.
Here's why we're not doing that first: We fundamentally believe that solving the "get any data questions answered instantly" problem is impossible without solving the data engineering problem first. Garbage in = garbage out. It's another shiny AI demo that does not deliver. Once you have an agent that is capable of understanding, updating and adapting every single piece of your data pipeline from source to action, while maintaining its own semantic layer connecting business logic to code & data, and communicating with your analyst(s) effectively, you are ready. Until you have that, you are not. We'll likely do a longer post on this soon, but for now suffice it to say that we're incredibly excited about this opportunity for both Nodal and its customers. It's just third on this list for a reason.
We could not be more excited about what we are building and what the future looks like when we've achieved this vision. In many ways, it's a version of the future many people envisioned in the mid-2010s as the modern data stack was getting going. Democratized data access, low barriers from integration idea to analysis, and the whole company participating in data production, definition & consumption.
Hope you'll consider becoming an early customer, or even just following along, and we appreciate your support!
Mike & Ron